
Fan of ChatGPT but prefer not to send data to OpenAI? Get started with the local version of ChatGPT. We’ll explain how to begin.
ChatGPT is powered by a LLM, short for Large Language Model. It runs on OpenAI’s servers where substantial computing power ensures you receive an immediate response to your query. The downside is that you’re using a cloud service. Your questions (and answers) are not private. It’s better not to send sensitive business data to form conclusions.
To still use ChatGPT, you can now use a downloadable version that is open source. Want to download and use it quickly? Unfortunately, it’s not that easy. Using a LLM locally requires specific tools.
For this how-to, we use Ollama, one of the most user-friendly options on the market. The screenshots you see here are from a Windows PC, but the steps are identical for Mac.
-
Step 1: Determine the Strength of your GPU
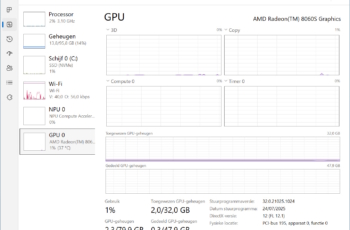 Before you enthusiastically start testing models, you first need to know if your PC is compatible. Running a LLM locally requires a lot of computing power and VRAM. The latter is the amount of memory of your graphics card (GPU). Simultaneously press Ctrl+Shift+Esc on a Windows PC and select GPU on the left. Under GPU memory centrally at the bottom, you can see how much your GPU is currently using of its memory and how much it has available in total.
Before you enthusiastically start testing models, you first need to know if your PC is compatible. Running a LLM locally requires a lot of computing power and VRAM. The latter is the amount of memory of your graphics card (GPU). Simultaneously press Ctrl+Shift+Esc on a Windows PC and select GPU on the left. Under GPU memory centrally at the bottom, you can see how much your GPU is currently using of its memory and how much it has available in total. -
Step 2: which Models Can You Run?
The higher the GPU memory, the better. You need at least 16 GB today to smoothly run the basic models. A complete overview of all LLMs compatible with this how-to can be found here. Each model has different variants, each with several billion parameters. Small models are identified by 1b, 0.6b, or 4b: respectively 1, 0.6, and 4 billion parameters. You can smoothly run these with a GPU with 16 GB of memory. The more parameters, the better the result. The open-source version of ChatGPT that you can run locally has 20 and 120 billion parameters respectively and carries the labels 20b and 120b.
OpenAI states that the 20b version of ChatGPT requires at least 16 GB. The 120b version needs a GPU with 80 GB. The latter is quite exotic and can only be found in Apple M-chips, Nvidia H100 GPUs, or an AMD Ryzen AI Max+ APU.
A handy rule of thumb: the number of parameters in billions roughly corresponds to the amount of memory your GPU needs to perform. Do you have limited GPU memory? Experiment with small models. Want to run ChatGPT locally? Then you need at least 16 GB.
The more parameters, the better the result. The open-source version of ChatGPT that you can run locally has 20 and 120 billion parameters respectively and carries the labels 20b and 120b.
OpenAI states that the 20b version of ChatGPT requires at least 16 GB. The 120b version needs a GPU with 80 GB. The latter is quite exotic and can only be found in Apple M-chips, Nvidia H100 GPUs, or an AMD Ryzen AI Max+ APU.
A handy rule of thumb: the number of parameters in billions roughly corresponds to the amount of memory your GPU needs to perform. Do you have limited GPU memory? Experiment with small models. Want to run ChatGPT locally? Then you need at least 16 GB. -
Step 3: Install Ollama
Before you start, download the correct version via this link: Windows, Linux, or macOS. In this guide, we continue with the Windows version. Click the button Download for Windows. The installation file is particularly simple: click Install. This prepares you to test LLMs on your PC.
-
Step 4: Download Language Models
Before we can use ChatGPT, the LLM must first be set locally. Start Ollama and select gpt-oss:20b on the right. Type Hello in the message window to start the download. At the time of writing, the model is 12.8 GB in size. Once the download is complete, ChatGPT will formulate a response. You can repeat the same for other models in the menu. Ollama’s graphical interface currently supports ChatGPT, Deepseek, Gemma, and Qwen. Other models can be called via the Windows Terminal, but we will not cover that in this how-to. We are now focusing on ChatGPT and the user-friendly interface of Ollama built for it.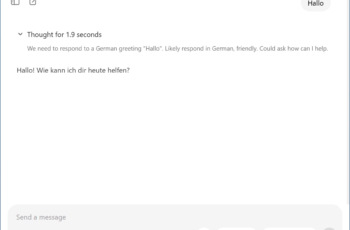
-
Step 5: Long Wait for Answers?
An LLM is, as the name suggests, a large language model with billions of parameters. Depending on how powerful your GPU is and how much memory it has, a response can take a long time. The complexity of your question also has an impact. The language doesn’t matter: French, Dutch, English, the model supports many languages. You can ask Ollama if it can help you with a summary of a project. The response to that will follow reasonably quickly. When you send the summary, the real work begins and it can sometimes take up to half an hour for the answer to arrive. Ollama and the local version of ChatGPT also have their limitations. You cannot upload files for analysis or generate images. For that, you can only use the online version of ChatGPT.
Do you sometimes have to wait minutes for an answer? Now you truly understand how powerful ChatGPT is in the cloud with millions of GPU “s ready for you. By running a model locally, you grasp the computing power required for language models. And the energy needed to drive (and cool) the GPU” s. Therefore, use the online version of ChatGPT wisely.
Fun detail: the local model of ChatGPT also provides its reasoning. You can literally follow how it wants to tackle a question and sometimes adds a critical note when you inquire about details or facts.
Meanwhile, OpenAI is preparing for the launch of GPT-5. GitHub has already leaked the first data.